




MongoDB has been a popular database among all NoSQL databases used these days for storing big data. Unlike relational databases, it may not provide techniques for defining good relationships but it provides flexibility in defining the schema of our collection, which is one of the core advantages of the platform.
Flexibility here is:
- No rules need to be followed
- No algorithms
- Can define the schema in an object format as you want.
A well-defined schema is very much important in MongoDB to query the data more efficiently with less hustle and improve the scalability as well. Unwanted schema objects may not impact your database at earlier stages but with the increasing amount of data, querying can slow down the performance and will acquire more memory.
Thus, keeping this in mind, a good schema design practice is needed. This article will help you understand the theoretical core concepts of MongoDB that can be used to improve scalability and performance along with the types of schema that can be defined.
What is MongoDB?
MongoDB is a document-oriented NoSQL database that can store large amounts of data in a JSON format in a collection and has a dynamic schema. It has a faster execution than RDBMS.
Schema Design Approaches – Relational vs MongoDB
Now, while defining schema across multiple databases most devs think that the approaches are similar, we store the data and then apply queries to fetch the same, well this is not how it works, schema is designed according to how we query the data and the functionality provided by the databases. You must first know how your application wants the data, for that let's first look into the approaches between Relational databases and MongoDB databases.
Relational Schema Design
Relational databases provide a good grasp of defining relationships which helps devs in only focusing on the data they have while building schema. The relationship is built by normalizing the data into multiple tables to remove redundancy and any data can be fetched according to the query we provide i.e using join. Look into the example below.
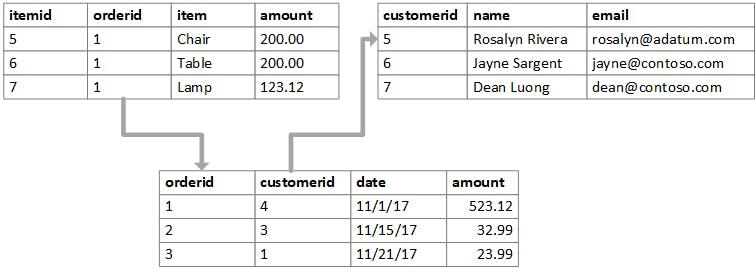
Data is normalized into tables and are joined using the foreign key concepts.
Embedding vs. Referencing in MongoDB
MongoDB data modeling depends upon the data that your application needs. Following are the key things that need to be considered while building a schema
- Store the data
- Provide good query performance
- Require a reasonable amount of hardware
In MongoDB, storing the data is directly proportional to querying the data, the way you keep is the same as the way you efficiently query for your application and that will improve the performance as well. Look into the example below.
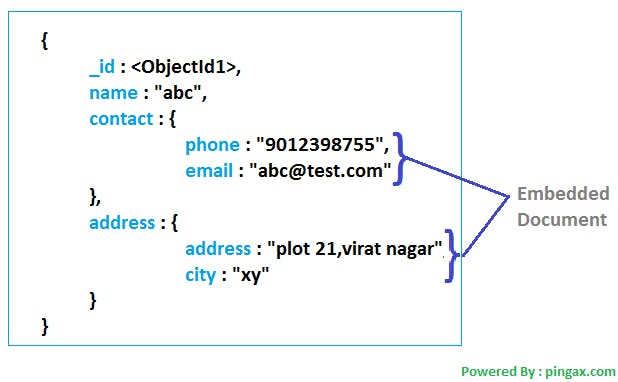
In MongoDB there is no normalization, the data is modeled in JSON format as we want, the child data is stored using an embedded document, or reference to the child table is stored using lookup. These are the two types through which data can be stored.
Embedding
Embedded documents are documents nested inside another document, also called nested documents within the collection.
Advantages
- Data retrieval will be faster with a single query from a single collection.
- Helpful in fetching small data.
- Increase the performance of the application
Limitations
- The document size limit is 16MB, and a large amount of embedded data cannot be stored exceeding its limit.
- If the nested document is large, it will be overhead to query the data.
Referencing
There is another approach alternative to Embedding, if the document size is quite large it's good to create a separate collection and give its reference to the parent collection’s document using a unique id and connecting through the $lookup operator that works similarly to the JOIN operator.
Advantages
- Less size of the documents < 16MB
- Reduce the data duplication
- Infrequently used information not needed in the query.
Limitations
- More than one query or $lookup operator will be needed to fetch the data from reference collection, which will be slower compared to embedding documents.
Type of Relationships
Relationships represent how the multiple documents are logically connected in MongoDB to create a more manageable database. This is not such as normalizing into tables but creating through embedded and referenced relationships. You can set up the relationship based on the need for your data and the performance of the query. Let’s look into the types of relationships
One to One
One-to-one is the most fundamental relationship to define. One parent key with one embedded child document creates a 1:1 relationship. For example, one person can have only one passport.
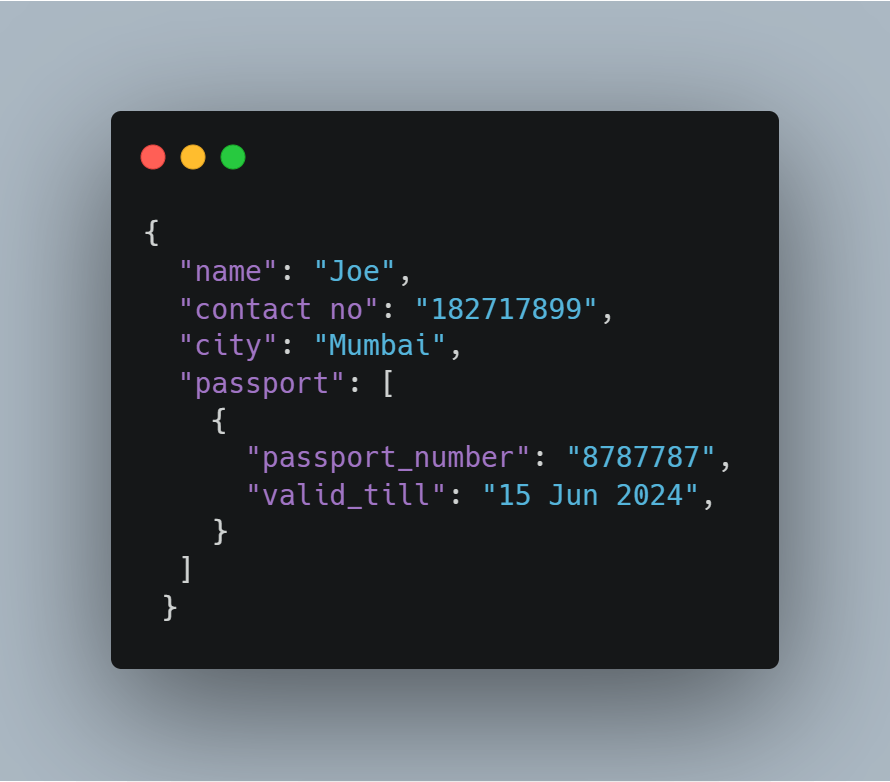
Here, the user’s passport details are embedded in the passport key, there is no need to create a separate collection until and unless the data is quite large.
One to Many
A one-to-many relationship is having a one-key of parent document with embedded or referenced child documents, creating a 1:N relationship. Suppose, a person can have multiple cars, for this, we can create relationships using embedding or referencing.
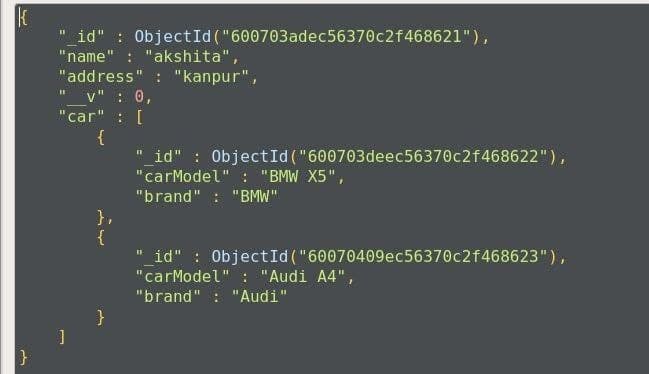
Here, the child data is embedded in the parent key ‘car’, if you want to get the data from the name of the person, then embedding would be better to use, as you only have to provide a single query to get the child data as well.
Referencing on the other side can be used to normalize the large data, creating a separate collection and referencing them would be a better fit for the query.
One-to-few
One-to-few relationships are used to connect the parent data with a few child data. Now, a single user can have multiple addresses, to store those few documents embedding relationships should be used for query performance.

One-to-Squillions
Now suppose you have millions of child records such as tweet replies, probably they would get larger and larger, for this we neither embed child documents nor store the arrays of referenced collection object Id, as it will be out of bound. The only preferred way will be to have a document of reply, then store the objectId of reply in the documents of the tweet. Look below for the example:
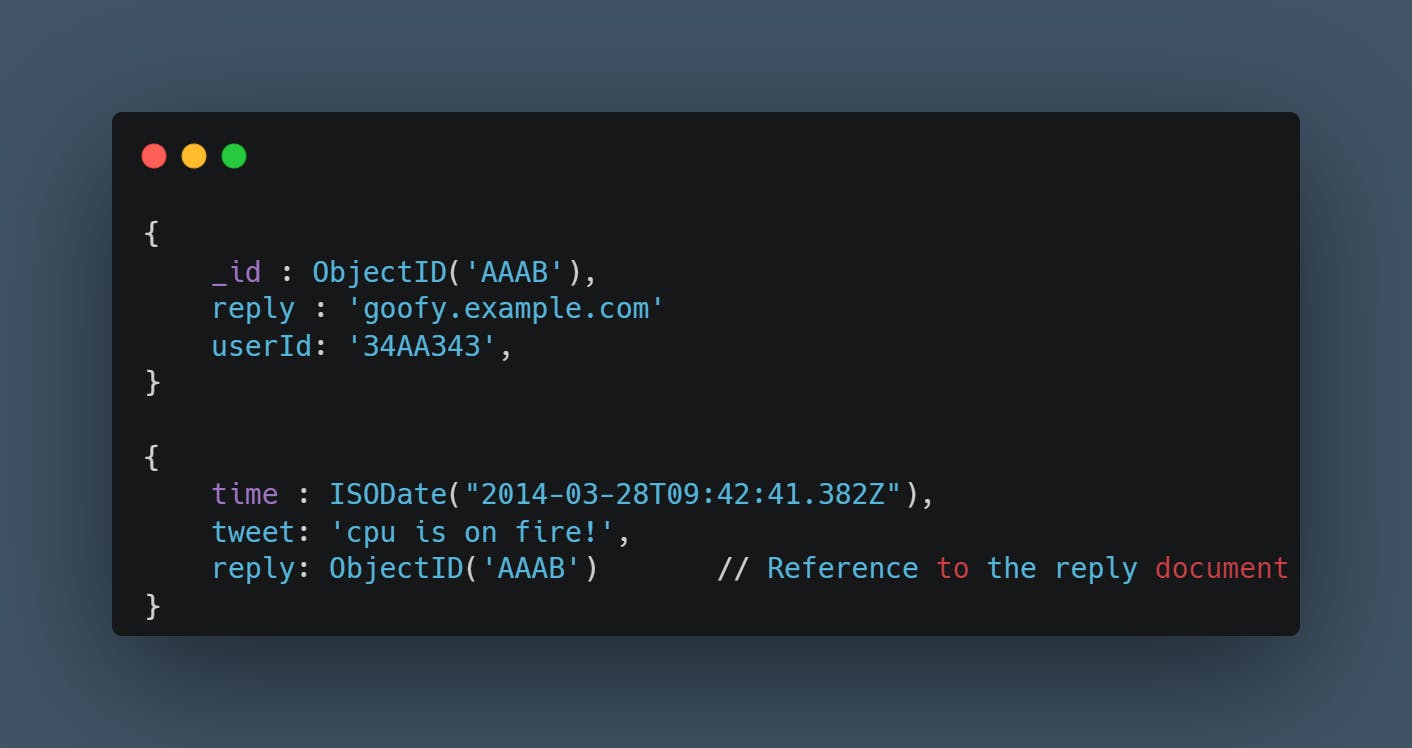
Many-to-Many
Now, that we have seen the single parent and different types of child documents, let’s look into the N: N relationship. Take an example of events, where a user can be invited to multiple events and an event can have multiple users.

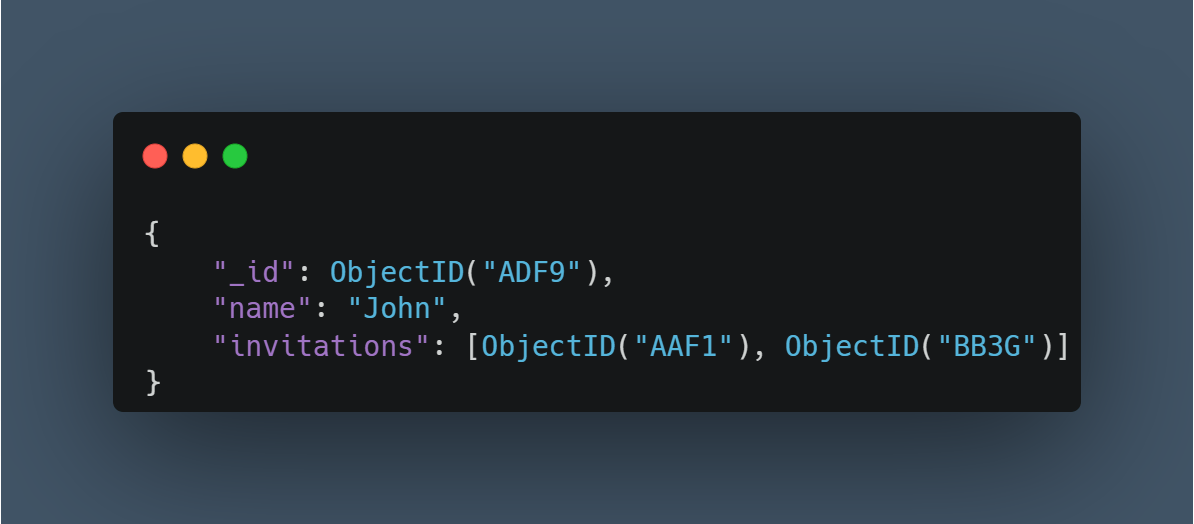
Here, in both the collections, there is a subarray of objectId, creating many-many relationships.
MongoDB best practices
Understanding query patterns and profiling
The most fundamental aspect of Mongodb is query pattern, very much important to know how your application needs your data to effectively get the data with better performance.
Profiling is a kind of debugging for MongoDB performance, you will get to know the issue and track its slow-running queries or transactions. Some profiling tools are MongoDump, MongoSkin, and Persona Monitoring and Management.
Review data modeling and indexing
MongoDB provides you to create a dynamic schema, but it would be beneficial if you create the schema precisely and accurately according to the needs of your data. It would be very costly if you don’t define your schema well enough earlier and you have to make the changes afterward down the road. Indexing in MongoDB will mostly be used for searching from the documents, instead of querying the whole document, indexes are created so that it gets easy to search from a few fields.
Ensure you are embedding and referencing
In relationships, embed the child data whenever possible, it will be beneficial for query performance as we don’t need to pass multiple queries to get from another collection. Embedding will improve the performance with the help of a single query.
Getting data from other related collections that store a large amount of data will be a query with the $lookup operator.
Ensuring these relationships will help you to get fruitful results and can easily handle the data.
Size the memory
MongoDB stores data into files of around 64MB or up to 2GB in size. These files are divided logically into different blocks stored in the virtual memory blocks. The data from virtual blocks are loaded into the memory map, where it leverages the system cache. These files are the data that your application is constantly requesting, these are called ‘Working sets’ in MongoDB. If the working set doesn’t fit in the memory, then the OS will need to swap one part of the Working set to disk, to access another part of it.
So if the working set exceeds the size of RAM, then either increase RAM or shard the MongoDB system, it will split the ‘Working set’ to multiple RAMs.
Use replication and sharding
Horizontal scaling is an approach to setting up multiple MongoDB machines to increase performance and scalability. As the data grow with the application it will be not possible to handle one database server with data accessibility, instead, MongoDB will store the records in multiple MongoDB machines keeping them in sync with automatic data failover in case the server fails.
Replication is to create multiple replicas of the server so that if one server fails, you will have a copy of the database on another server. For replicas, the entire data volume must be stored in a single server, so that we can get a 100% copy of data in case of server failure.
Conclusion
The 'Schema design best practices' can be defined as an effective solution to the problem of structuring the data in a database and making it consistent by avoiding redundancy and preserving data integrity.
Designing the right schema model seems quite tricky, where various concepts and terms such as ACID vs BASE vs BASEPROPERTIES, dynamic schema, and how to handle the different scenarios of schema design to build a robust production system. All that information seems confusing at first glance, but I've organized them as best practices in my article that explains what you need to know about MongoDB schema design.